Benchmarking LLMs on the Vulnerability Prioritization Task
LLMs underperform EPSS in estimating vulnerability exploitation in the next 30 days, and significantly underperform the Empirical Security Global Model. When considering inference cost, they just aren’t worth the squeeze.
We built an LLM agent (with inference provided by OpenRouter) to estimate the probability (0.0 – 1.0) that a supplied CVE will be exploited in the next 30 days. CVE data is fetched from the CIRCL CVE Search API and injected into the prompt. JayPT (as we call the agent) then scored a sample of 50,000 CVEs stratified by EPSS score and by exploitation activity.
The distributions of scores generated by LLMs are lumpy and skewed upwards. The lack of granularity in scores makes them harder to use for decision making as we’ll see below. Generally speaking, an upward skewed distribution would indicate over-estimatation of the probability, but it seems all three LLMs both over and underestimate probability of exploitation often.
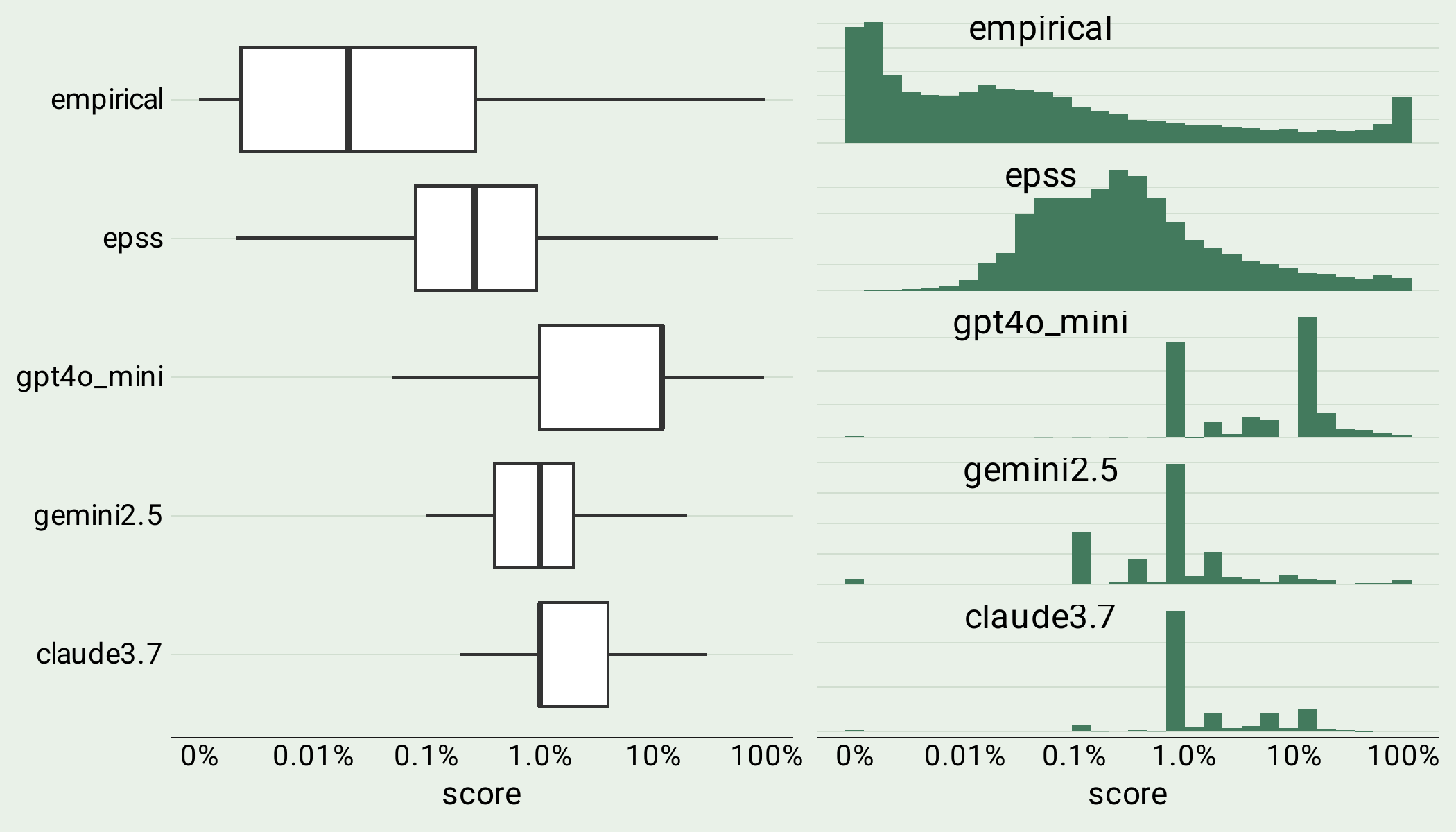
LLM generated probabilities skew upwards.
Next we examine the coverage and efficiency of all five models. GPT4o mini, Claude 3.7 and Gemini 2.5 all fail to cross the 70% efficiency threshold at any coverage level. What’s worse is they sharply dropoff in efficiency after about 15% coverage, likely because once any publicly available data on known exploitation can’t be found. A predictive model, like EPSS, continues a smooth tradeoff between efficiency and coverage and performs consistently throughout the coverage range. Keep in mind another advantage of both EPSS and our model is that they are calibrated probabilities, whereas calibration for an LLM would be costly.
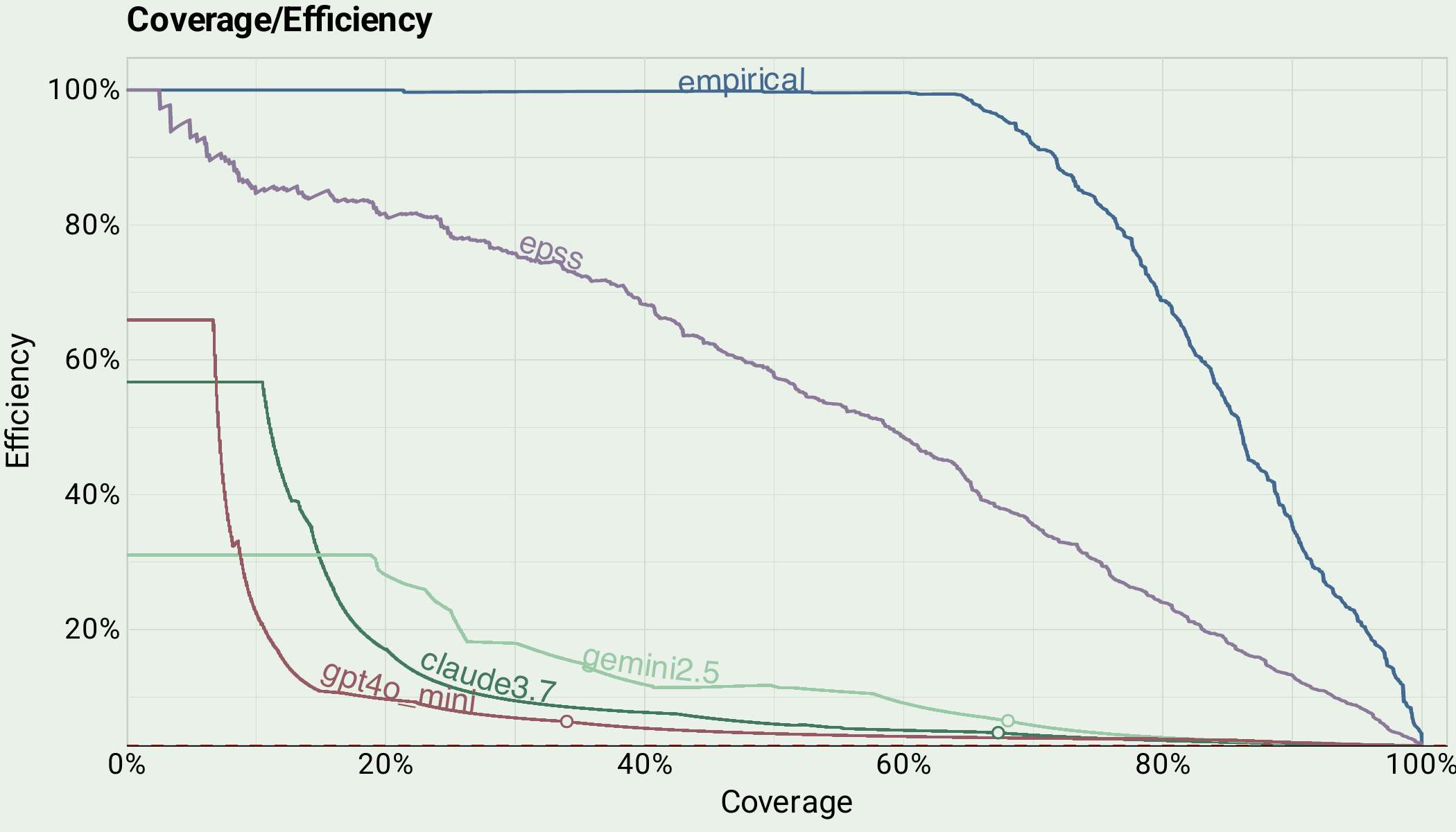
LLMs lack the efficiency needed for the vulnerability prioritization task, the explanation is a tautology: prediction requires predictive modeling. Vulnerability prioritization is inherently a predictive task (“will an event occur?”).
Before we wrap up our analysis, a note about the cost. Our staff engineer, Joseph, built JayPT to design its own prompts. As you’ll see in the repo, the prompts are analyzed for their performance by the LLMs before generating a new one. “Respond with your analysis of the prompt that just ran, its performance, and ideas you have for improving it.” Given that we’re evaluating each model on a triage task, we also need to evaluate the cost. The dataset of 50,000 CVEs scored by LLMs is available for inspection in the repo as well, and it cost $2400 in openrouter credits to generate. That may seem reasonable, until we think about a vulnerability management team using a model in this way. Scaling up to 250k CVEs, and updating the scores hourly gets us to $2400*5*24 = $288,000 per day just to generate the probabilities for three rather cheap models. EPSS, of course, is free.
The last chart is the clearest one. Assuming your organization has a limited amount of CVEs they could remediate, let’s say 10% of all of the ones in NVD (no small feat), you’d see about 20% coverage with gpt4o mini and claude 3.7, and about 35% with gemini 2.5. EPSS will get you to 80% coverage for the same amount of effort, and our Global model can get to 95%. Also of note are the lumpy coverage levels in the LLMs. They have limited output values, meaning prioritization changes appear in "steps" rather than smoothly as thresholds are applied.

Limited coverage of LLMs on the vulnerability prioritization task.
Today we’re releasing the agent, as well as the benchmark scores for the research and academic communities to use to benchmark models on the vulnerability prioritization task. We want to make it clear that we don’t think using this agent or LLMs in general for the vulnerability prioritization task is a good idea, but we wanted to prove that with data and action rather than theory.
Available here under an MIT license, JayPT https://github.com/empiricalsec/JayPT is a large-language-model agent channeling the analytic style of cybersecurity researcher and our co-founder Jay Jacobs.